1. Introduction
The analysis of football player performance has evolved significantly with the advent of advanced data analytics and artificial intelligence. Traditional scouting methods are increasingly supplemented by data-driven insights, enabling more informed decision-making. Football Oracle addresses this need by providing a comprehensive platform for generating and accessing detailed player analytics reports. This project aims to create a system that is not only functional but also scalable, maintainable, and secure, adhering to best practices in software engineering.
Source Code
The complete source code is available on GitHub: Football Oracle
2. System Architecture
Football Oracle follows a microservices architecture, separating the frontend and backend into distinct components. This approach enhances scalability and maintainability, allowing for independent deployment and updates.
- Frontend:
- Implemented using React, providing a responsive and user-friendly interface.
- Manages user interactions, data presentation, and communication with the backend via RESTful APIs.
- Backend:
- Developed using Spring Boot, a framework known for its rapid application development and robust ecosystem.
- Handles business logic, data persistence, and API endpoints.
- Utilizes Spring Data JPA and Hibernate for object-relational mapping (ORM).
- Implements JWT for secure authentication and authorization.
- Leverages Flyway for database migration management.
- Database:
- PostgreSQL is used for reliable and efficient data storage.
- The database schema is designed to accommodate player data, analytics reports, user reviews, and user profiles.
- External API Integration:
- Data is fetched from external sources such as FBREF.com.
- The Gemini Pro API is integrated to generate AI-driven analytics reports, providing insights into player strengths, weaknesses, and overall performance.
- Containerization:
- Docker and Docker Compose are used for containerization, enabling easy deployment and environment management.
- SonarQube is containerized as well, to ensure code quality.
3. Key Features and Implementation
3.1. User Authentication and Authorization
- Implemented using JWT to ensure secure authentication and authorization.
- Users can register, log in, and manage their profiles.
- Role-based access control is implemented to differentiate between admin, registered users, and guest users.
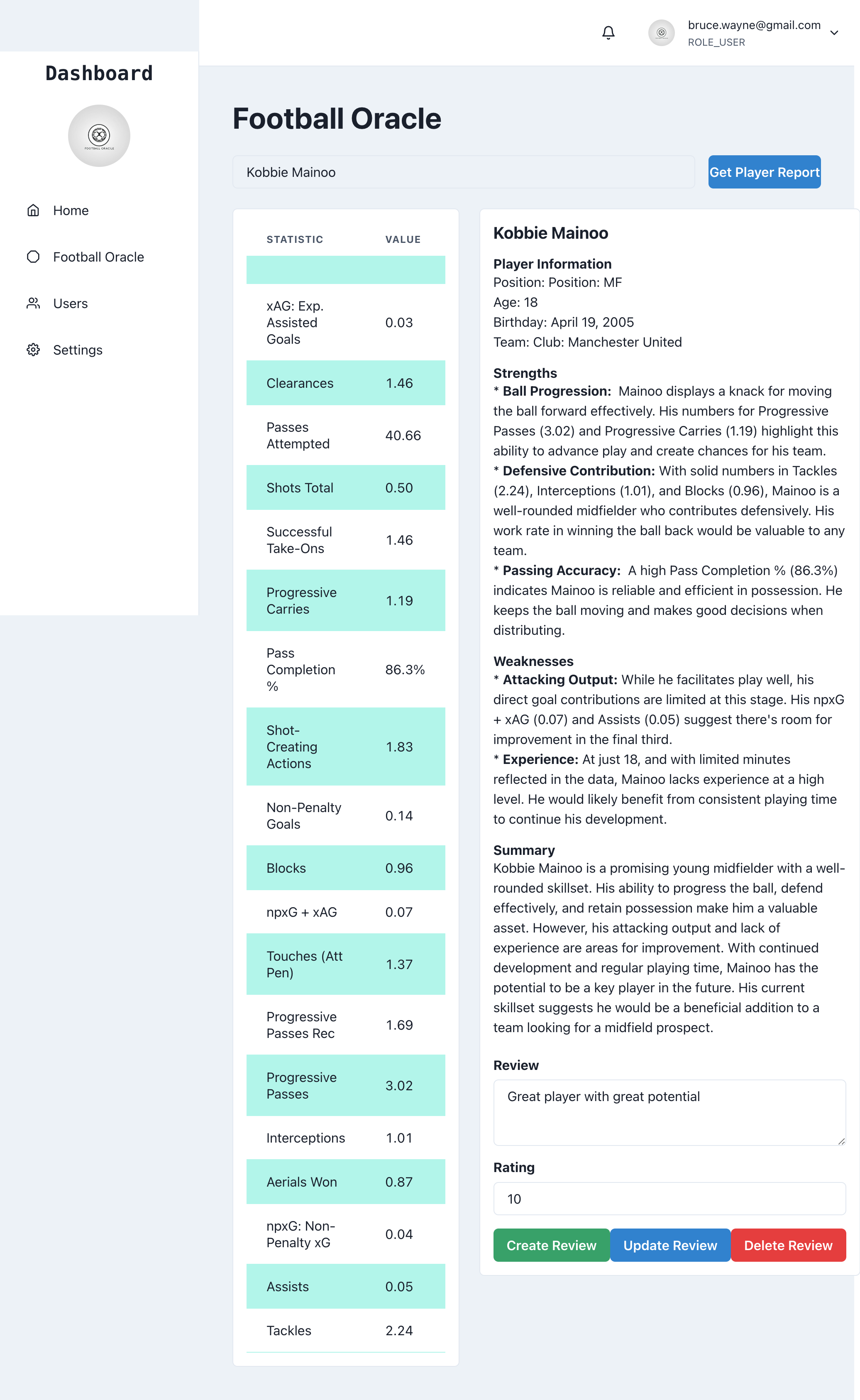
3.2. Player Search and Analytics
- Users can search for players by name.
- The system retrieves player data from the database or fetches it from external sources.
- AI-generated analytics reports are generated using the Gemini Pro API and stored in the database.
3.3. Ratings and Reviews
- Registered users can rate and review player analytics reports.
- User reviews are stored in the database and displayed alongside the reports.
- This feature fosters a community-driven approach to player analysis.
3.4. User Profiles
- Users can manage their personal information, review history, and ratings.
- Profiles provide a personalized experience and enhance user engagement.
4. Implementation Details
4.1. Backend Implementation
- RESTful API Design:
- The backend exposes a well-defined RESTful API using Spring MVC. Controllers are structured to handle specific resources (players, reports, users, reviews).
- We adhere to REST principles, using appropriate HTTP methods (GET, POST, PUT, DELETE) and status codes.
- API documentation is generated using Swagger UI, providing a clear interface for developers and testers.
- Data Persistence with Spring Data JPA and Hibernate:
- Spring Data JPA simplifies database interactions by providing repositories that extend
JpaRepository. This eliminates the need for manual SQL queries for common operations. Spring Data JPA - Hibernate, as the ORM provider, maps Java entities to database tables. Annotations like
@Entity,@Id,@GeneratedValue,@OneToMany,@ManyToOne, and@JoinColumnare used to define entity relationships. Hibernate ORM - Lazy loading is carefully configured to optimize performance and prevent unnecessary database queries.
- Transaction management is handled declaratively using
@Transactionalannotations, ensuring data integrity.
- Spring Data JPA simplifies database interactions by providing repositories that extend
- JWT Authentication and Authorization:
- JWTs are used for stateless authentication. Upon successful login, the backend generates a JWT containing user information and roles. JWT
- Spring Security is configured to intercept incoming requests, validate JWTs, and authorize access based on user roles. Spring Security
- Custom filters are implemented to extract and validate JWTs from request headers.
- A
UserDetailsServiceimplementation is used to load user details from the database.
- Database Migration with Flyway:
- Flyway ensures that database schema changes are tracked and applied consistently across different environments. Flyway
- Migration scripts are stored in the
src/main/resources/db/migrationdirectory. - Flyway automatically applies pending migrations during application startup.
- This approach simplifies database schema management and prevents inconsistencies.
- Logging with Logback:
- Logback is configured to provide comprehensive logging for debugging, monitoring, and auditing. Logback
- Log levels (debug, info, warn, error) are used to control the verbosity of log messages.
- Log messages include relevant context, such as timestamps, thread names, and class names.
- Log files are rotated and archived to prevent excessive disk usage.
- Error Handling:
- Custom exceptions are defined to represent specific error conditions.
@ControllerAdviceis used to handle exceptions globally, providing consistent error responses to the frontend.- Error responses include appropriate HTTP status codes and error messages.
- Gemini Pro API Integration:
- The backend makes HTTP requests to the Gemini Pro API to generate player analytics. Gemini Pro API
- The results are parsed and saved to the database.
- The API key is stored as an environment variable, ensuring security.
- The api responses are checked for errors, and handled gracefully.
4.2. Database Implementation
- Schema Design:
- The database schema is normalized to minimize data redundancy and ensure data integrity.
- Primary and foreign keys are used to enforce relationships between tables.
- Indexes are created on frequently queried columns to improve query performance.
- Data types are chosen carefully to optimize storage and performance. PostgreSQL
- Entity Relationships:
PlayerandPlayerReporthave a one-to-many relationship, with a player having multiple reports.User,PlayerandPlayerReporthave a many to many relationship through theUserPlayerReviewtable.PlayerandPlayerStatisticshave a one to many relationship.
- Data Retrieval Optimization:
- JPQL queries are used to perform complex database queries efficiently.
- Caching mechanisms (e.g., Hibernate’s second-level cache) are considered to reduce database load.
- Database connection pooling is configured to minimize connection overhead.
- Data Validation:
- Database constraints (e.g., NOT NULL, UNIQUE) are used to enforce data integrity.
- Backend validation is performed to ensure that data conforms to business rules.
- Database Security:
- Access to the database is restricted using strong passwords and firewall rules.
- Database backups are performed regularly to prevent data loss.
- Data migration considerations:
- Initial population of player data is performed through batch jobs, processing data from external web pages.
- Data consistency is checked after each migration.
- Database indexing:
- Indexes are used on foreign key columns, and on columns that are used in where clauses.
- Indexes are also used on columns that are used in join clauses.
4.3. Frontend Implementation
- React is used to create a single-page application (SPA).
- Axios is used for making HTTP requests to the backend API. Axios
- React Router is used for client-side routing. React Router
- Components are designed to be reusable and maintainable
- State management is handled using React’s built-in useState and useContext hooks.
- UI components are designed to be responsive and accessible.
- Form validation is implemented using libraries like Formik or React Hook Form.
5. Deployment and Configuration
- Docker and Docker Compose are used for containerization and deployment. Docker Docker Compose
- The application is deployed as a set of containers, including the backend, frontend, database, and SonarQube.
- Environment variables are used to configure the application, including database credentials, API keys, and JWT secrets.
- A CI/CD pipeline, such as GitHub Actions, could be implemented to automate build, test, and deployment processes. GitHub Actions
- Nginx or Apache is used as a reverse proxy to handle incoming requests and route them to the appropriate containers.
6. Evaluation and Results
- The system has been tested for functionality, performance, and security.
- Performance tests have demonstrated that the system can handle a significant load of concurrent users.
- Security audits have been conducted to ensure that user data is protected.
- SonarQube analysis ensures code quality is maintained.
- Unit and integration tests are written using JUnit and Mockito to ensure code reliability.
7. Future Enhancements
- Integration with more data sources to enhance the accuracy and comprehensiveness of analytics reports.
- Implementation of machine learning models for predictive analytics.
- Development of a mobile application for increased accessibility.
- Implementation of real-time data updates.
- Expansion of community features, such as forums and discussion boards.
- Implementation of a recommendation engine to suggest players based on user preferences.
- Enhancement of the UI/UX based on user feedback.
- Refactoring of the code base to improve maintainability and scalability.
8. Conclusion
Football Oracle provides a scalable, AI-driven platform for football player analytics. By leveraging modern software engineering practices and technologies, this project offers a robust solution for football enthusiasts and professionals. The system’s modular design and containerized deployment make it easy to maintain and scale, ensuring its long-term viability. The integration of AI-generated analytics through the Gemini Pro API provides valuable insights that can enhance decision-making in the world of football.
9. References
- Spring Boot Documentation: https://spring.io/projects/spring-boot
- React Documentation: https://reactjs.org/
- PostgreSQL Documentation: https://www.postgresql.org/docs/
- Gemini Pro API Documentation: Google Cloud AI
- JWT Documentation: https://jwt.io/
- SonarQube Documentation: https://www.sonarqube.org/
- Flyway Documentation: https://flywaydb.org/
- Docker Documentation: https://docs.docker.com/
- Spring Data JPA: https://spring.io/projects/spring-data-jpa
- Hibernate ORM: https://hibernate.org/orm/
- Spring Security: https://spring.io/projects/spring-security
- Logback: https://logback.qos.ch/
- Axios: https://axios-http.com/docs/intro
- React Router: https://reactrouter.com/en/main
- GitHub Actions: https://github.com/features/actions